Apache Kafka vs. Redis Streams: Differences & Comparison
Redis Streams and Apache Kafka are two popular technologies for handling real-time data streaming and messaging. While they share some functional similarities, they differ significantly in architecture, performance characteristics, and ideal use cases. This comprehensive comparison examines their differences, implementation details, performance considerations, and best practices to help you make an informed decision for your streaming data needs.
Apache Kafka is a distributed streaming platform designed specifically for high-throughput, low-latency data streaming[5]. Developed initially by LinkedIn and later donated to the Apache Software Foundation, Kafka has become the industry standard for building real-time data pipelines and streaming applications[14].
Kafka's architecture consists of several key components:
-
Brokers : Servers that store data and serve client requests
-
Topics : Categories for organizing message streams
-
Partitions : Subdivisions of topics that enable parallel processing
-
Producers : Applications that publish messages to topics
-
Consumers : Applications that subscribe to topics to process data
-
Consumer Groups : Collections of consumers that work together to process messages[4]
Kafka stores messages on disk by default, providing durability and persistence while still maintaining high throughput[9].
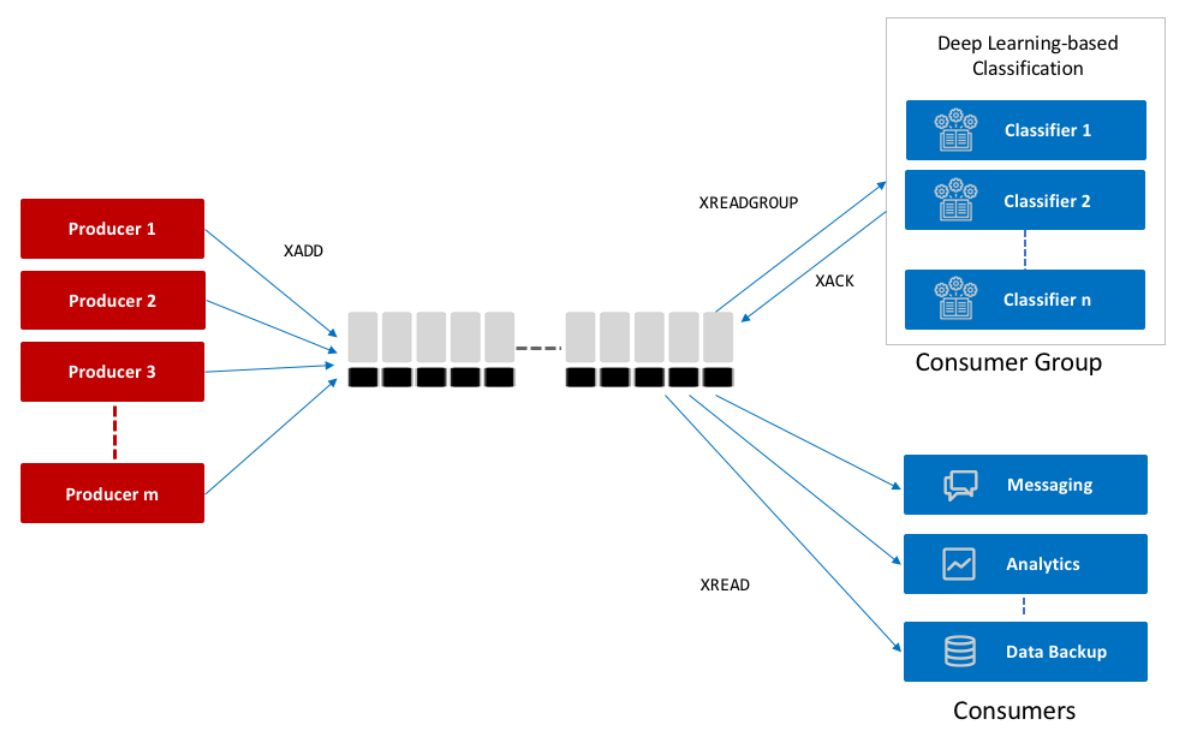
Redis Streams is a data structure introduced in Redis 5.0 that acts as a log-like append-only data structure[11]. As part of Redis, an in-memory data store, Redis Streams inherits its speed and simplicity while adding specific features for handling time-ordered data streams.
The core architecture of Redis Streams includes:
-
Stream Entries : Messages with unique IDs in the format
timestamp-sequence -
Field-Value Pairs : The data structure of each entry
-
Consumer Groups : Similar to Kafka, allows distributed processing
-
Pending Entries List (PEL) : Tracks entries delivered but not acknowledged[11]
As part of Redis, Streams operates primarily in-memory with optional persistence, making it extremely fast but more constrained by available RAM compared to Kafka[9][11].
|
Attribute |
Redis Streams |
Apache Kafka |
|---|---|---|
| Data Storage |
In-memory with optional persistence |
Disk-based with in-memory caching |
| Latency |
Sub-millisecond (extremely low) |
Low (but higher than Redis) |
| Throughput |
High (limited by memory) |
Very high (designed for high throughput) |
| Scalability |
Limited by Redis clustering capabilities |
High scalability with partitioning |
| Data Retention |
Typically shorter term (hours to days) |
Long-term storage capabilities (days to years) |
| Memory Efficiency |
High |
Memory used primarily for caching |
| Processing Model |
Single-threaded event loop |
Distributed processing |
Kafka Workflow :
-
Producers publish messages to brokers, which categorize data into topics and store in partitions
-
Consumers connect to relevant topics and extract data from corresponding partitions
-
Topics are divided across multiple brokers for scalability and fault tolerance[9][10]
Redis Streams Workflow :
-
Uses a client-server architecture with keys and primary-secondary nodes
-
Producers use
XADDto append entries to streams -
Consumers use
XREADorXREADGROUPto retrieve messages -
Supports consumer groups similar to Kafka, but with different implementation details[9][11][16]
-
Processing less than 1TB of data per day
-
Seeking simplicity in deployment and operations
-
Message history needs are moderate (hours to days)
-
Already using Redis for other components
-
Sub-millisecond processing is required
-
Working with simpler streaming needs in a familiar Redis environment[11]
-
Processing more than 1TB of data per day
-
Long-term storage (days to years) is needed
-
Requiring integration with Hadoop, Spark, or other big data tools
-
Advanced partition management is required
-
Cross-datacenter replication is essential
-
Building complex, large-scale data pipelines[11][5]
Both systems implement consumer groups, but with different approaches:
Kafka Consumer Groups :
-
Assign partitions to consumers statically
-
If a consumer fails, the group coordinator triggers a rebalance
-
Each partition is processed by exactly one consumer in a group[4][8]
Redis Streams Consumer Groups :
-
Created with
XGROUP CREATEcommand -
Maintain a "Pending Entries List" (PEL) for tracking unacknowledged messages
-
Support runtime consumer handling - if one consumer fails, Redis continues serving others[11][15][16]
# Creating a consumer group in Redis
XGROUP CREATE mystream mygroup 0
# Reading from the stream using the consumer group
XREADGROUP GROUP mygroup consumer1 STREAMS mystream >
Kafka :
-
Persists all data to disk by default
-
Uses a log-structured storage model with segment files
-
Retains messages for configurable periods (days to years)
-
Provides strong durability guarantees[5][9]
Redis Streams :
-
Primarily in-memory with optional persistence
-
Persistence options include AOF (Append-Only File) and RDB (Redis Database)
-
Memory is the primary limiting factor
-
Can be configured with
MAXLENto automatically trim older entries[11][16]
# Writing to a Redis stream with a cap on its length
XADD mystream MAXLEN ~ 1000 * field value
-
Partition Optimization :
-
Increase partitions for higher parallelism
-
Balance between too few (limited parallelism) and too many (overhead)
-
Consider the relationship between partitions and consumer groups[6]
-
-
Producer Configuration :
-
Adjust
batch.sizefor throughput vs. latency tradeoff -
Configure
linger.msto allow batching for better throughput -
Use appropriate compression settings for your workload[6]
-
-
Consumer Configuration :
-
Set appropriate
fetch.min.bytesandfetch.max.wait.ms -
Configure consumer
max.poll.recordsbased on processing capabilities -
Consider thread count and processing model[6]
-
-
Memory Management :
-
Use
XTRIMto limit stream length and prevent memory issues -
Use approximate trimming for efficiency with
~symbol -
Configure
stream-node-max-bytesto control per-node memory usage[11]
-
# Limit stream length to prevent memory issues
XTRIM mystream MAXLEN ~ 100000
-
Consumer Group Optimization :
-
Process messages in batches (10-100 entries)
-
Acknowledge messages in batches to reduce network round-trips
-
Set appropriate timeouts for blocking operations[11]
-
-
Monitoring Metrics :
-
Track stream length and details with
XINFO STREAM -
Monitor consumer group status with
XINFO GROUPS -
Check individual consumer lag with
XINFO CONSUMERS[11]
-
Kafka :
-
Monitor consumer lag metrics using Kafka's monitoring tools
-
Scale consumer groups horizontally to improve processing throughput
-
Optimize consumer configurations and processing logic[6]
Redis Streams :
-
Monitor pending entries list (PEL) for growing backlog
-
Add more consumer instances to scale processing
-
Enable batch acknowledgment using
XACKwith multiple IDs[11]
Kafka :
-
Less susceptible to memory pressure due to disk-based storage
-
Monitor broker heap usage and GC patterns
-
Adjust JVM parameters as needed[6]
Redis Streams :
-
Critical concern due to in-memory nature
-
Use auto-trimming with
XTRIMto manage historical data -
Monitor Redis memory usage via
INFO memorycommand -
Consider Redis cluster deployment for horizontal scaling[11][12]
Kafka :
-
Configure appropriate replication factor (typically 3)
-
Set proper
acksvalue for producers (usuallyallfor critical data) -
Implement idempotent producers for exactly-once semantics[5]
Redis Streams :
-
Be aware of replication limitations - asynchronous replication doesn't guarantee all commands are replicated
-
Implement client retry mechanisms for critical messages
-
Enable AOF persistence as 'always' for improved durability[11][15]
Kafka achieves horizontal scalability through:
-
Distributing partitions across brokers
-
Adding more brokers to a cluster to increase capacity
-
Allowing consumer groups to parallelize processing
-
Supporting cross-datacenter replication[5][9]
Redis Streams scaling options include:
-
Sharding streams across multiple Redis nodes
-
Using Redis Cluster for automatic partitioning
-
Implementing client-side sharding strategies
-
Leveraging consumer groups for parallel processing[11][12]
# Example pseudo-code for sharding in Redis Streams
shard_id = hash_func(data) % num_of_shards
redis_clients[shard_id].xadd(stream_name, data)
Both Apache Kafka and Redis Streams offer powerful capabilities for handling streaming data, but they excel in different scenarios.
Kafka stands out for large-scale, distributed applications requiring long-term message retention, high durability, and extensive ecosystem integration. Its robust architecture makes it ideal for enterprise-grade applications with complex data pipelines and high-volume throughput requirements[5][9][17].
Redis Streams shines in scenarios requiring extreme low latency, simpler deployment, and when working within an existing Redis infrastructure. Its in-memory nature makes it exceptionally fast but more constrained by memory availability, making it better suited for scenarios with moderate data volumes and shorter retention needs[11][16][17].
The choice between these technologies should be guided by your specific requirements around data volume, retention needs, latency sensitivity, and existing infrastructure. For many organizations, they may even complement each other, with Redis Streams handling ultra-low-latency requirements while Kafka serves as the backbone for broader data streaming needs.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
