Confluent Current 2025: Key Innovations in Kafka & Flink
Confluent's flagship event, Current 2025 in Bengaluru, delivered significant product announcements including Tableflow advancements and general availability of Confluent Cloud for Apache Flink. The event, formerly known as Kafka Summit Bangalore, marked the first Current conference in the Asia-Pacific region, highlighting India's growing importance in the global data streaming ecosystem. With 45 speakers across 35+ sessions, the conference showcased how organizations are leveraging data streaming technologies for real-time applications and generative AI use cases, featuring success stories from companies like Swiggy and announcing strategic partnerships with Databricks and Jio Platforms.
Confluent Current 2025 made its debut in Bengaluru, India on March 19, 2025, at the Sheraton Grand Bengaluru Whitefield, marking a significant milestone as the first-ever Current conference in the Asia-Pacific region[1][2]. The event, previously known as Kafka Summit Bangalore, brought together 45 speakers who delivered more than 35 dynamic sessions focused on data streaming technologies[1][3]. This transformation from Kafka Summit to Current Bengaluru reflects the evolution of Confluent's vision beyond Kafka to encompass a broader data streaming ecosystem.
The conference timing is particularly notable as it represents Confluent's decision to kick off its 2025 global series from India, underscoring the country's strategic importance in the data streaming landscape[1]. As Kamal Brar, Senior Vice President, APAC at Confluent, emphasized, India represents "a critical hub for the global data streaming community"[3]. The event's location in Bengaluru, often considered India's technology capital, further reinforces this strategic focus on the region's growing technological capabilities and market potential.
The conference featured keynote sessions delivered by Confluent's leadership team, including Jay Kreps, Co-founder and CEO, and Shaun Clowes, Chief Product Officer[1][2]. These sessions not only outlined Confluent's product roadmap but also highlighted the company's vision for the future of data streaming technologies in powering real-time applications and AI-driven innovations across various sectors and use cases.
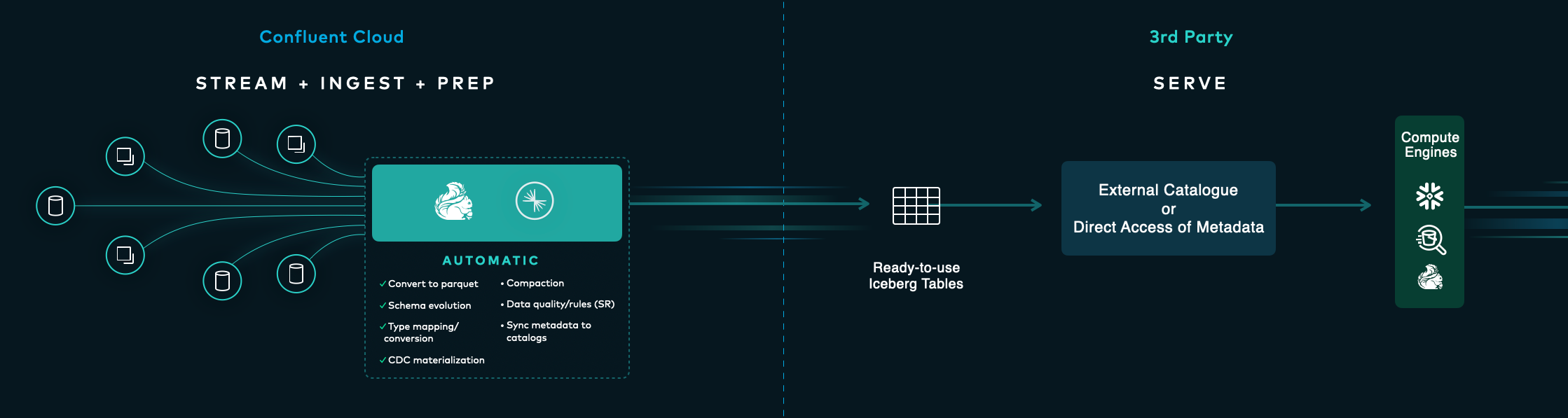
One of the most significant announcements at Current Bengaluru was the advancement of Tableflow, Confluent's solution for accessing operational data from data lakes and warehouses[7]. This technology breakthrough enables streaming data in Confluent Cloud to be accessed in popular open table formats, creating new possibilities for analytics, real-time AI, and next-generation applications[7]. The announcement marked a critical step in Confluent's vision to bridge the gap between operational and analytical data systems.
Tableflow's general availability for Apache Iceberg support represents a major milestone, allowing organizations to leverage this open table format for their streaming data needs[7]. Additionally, through an expanded partnership with Databricks, Confluent announced an early access program for Delta Lake integration, further extending Tableflow's capabilities[7][10]. These developments are complemented by enhanced data storage flexibility and seamless integrations with leading catalog providers, including AWS Glue Data Catalog and Snowflake's managed service for Apache Polaris[7].
The strategic importance of Tableflow lies in its ability to continuously update tables used for analytics and AI with the exact same data from business applications connected to Confluent Cloud[7]. This ensures that analytical systems and AI applications are powered by the most current, high-quality data, addressing a fundamental challenge in enterprise data architecture where operational and analytical systems are often disconnected or poorly synchronized.
The general availability announcement of Confluent Cloud for Apache Flink across AWS, Google Cloud, and Microsoft Azure platforms marked another major highlight of the event[8]. This fully managed service enables organizations to process data in real-time and create high-quality, reusable data streams without the complexities of infrastructure management[8]. With this release, Confluent strengthens its position as a leading provider of cloud-native, serverless Flink services.
Confluent Cloud for Apache Flink enables customers to effortlessly filter, join, and enrich data streams using Flink, which has become the de facto standard for stream processing[8]. The service promises high-performance and efficient stream processing at any scale, without the complexities of infrastructure management that traditionally burden organizations implementing such solutions[8]. Furthermore, it offers Kafka and Flink as a unified platform with fully integrated monitoring, security, and governance capabilities[8].
The significance of this announcement extends to several key use cases highlighted during the conference. These include creating streaming data pipelines for vector databases to support generative AI applications, enabling more accurate real-time alerts for event-driven applications, and powering faster decisions through real-time analytics[8]. Organizations across various sectors, from food delivery services to financial institutions, can leverage these capabilities to transform their operations and customer experiences.
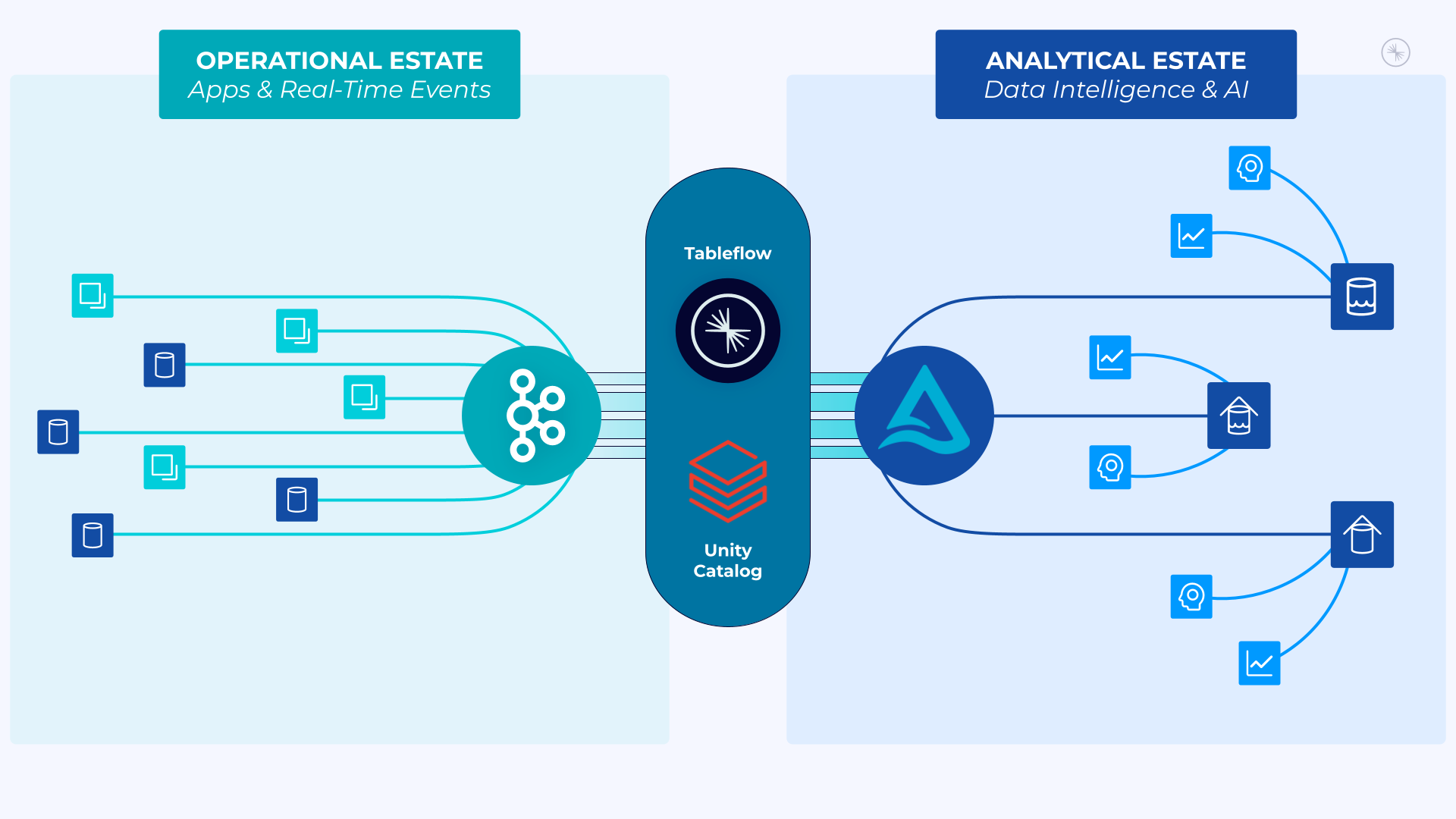
The expansion of Confluent's partnership with Databricks emerged as a central theme at Current Bengaluru 2025, focusing on integrating their respective data streaming and intelligence platforms to enable real-time AI-driven decision-making for enterprises[10]. This strategic collaboration directly addresses a critical market gap revealed in their research: only 22% of enterprises currently feel confident that their IT infrastructure can support new AI applications[10].
The enhanced partnership introduces new integrations between Confluent's Tableflow and Databricks' Unity Catalog, providing bidirectional integration with Delta Lake[10]. This technical architecture offers three key advantages: bidirectional data flow enabling real-time operational data synchronization, unified governance through Unity Catalog integration, and automated metadata management for enhanced data discovery[10]. By combining Confluent's expertise in real-time data streaming with Databricks' leadership in data lakehouse architecture, the partnership aims to fundamentally transform how organizations implement and leverage AI capabilities.
This collaboration positions both companies to capture a larger share of the rapidly growing enterprise AI market[10]. For Confluent, it extends their reach beyond traditional data streaming into the AI/ML workflow ecosystem, while for Databricks, it strengthens their data lakehouse architecture with robust real-time streaming capabilities essential for modern AI applications[10]. The integration fundamentally changes the economics of enterprise AI implementation by eliminating the need for custom integration development and reducing data engineering overhead.
Confluent's growing commitment to the Indian market was highlighted through strategic regional partnerships announced at the event. Notably, the company has partnered with Jio Platforms to support Jio Cloud Services, making Confluent Cloud available in the Jio India West region for Indian businesses[9]. This partnership enables local organizations to leverage Confluent's data streaming capabilities while meeting regional data sovereignty and performance requirements.
The event also showcased how Confluent is powering India's startup ecosystem, with partnerships featuring prominent companies such as Swiggy, Mobile Premier League (MPL), Meesho, PhonePe, Dream11, and Shiprocket[5][9]. These collaborations demonstrate Confluent's growing influence in India's technology landscape and its role in enabling digital transformation across various sectors of the Indian economy.
The most comprehensive customer case study featured at Current Bengaluru was Swiggy, India's leading on-demand convenience platform serving millions across nearly 700 cities[14][15]. Swiggy has implemented Confluent's fully managed data streaming platform to manage over 3 billion orders efficiently, requiring instant insights and precise coordination between restaurants, delivery partners, and consumers[15].
By transitioning from open-source Apache Kafka to Confluent's managed cloud service, Swiggy achieved several significant improvements in their operations[14]. The shift freed their data team from infrastructure maintenance burdens, allowing them to focus on innovation rather than system upkeep[14]. One concrete example highlighted was Swiggy's ability to provide precise delivery ETAs in their app by processing live data from restaurants, delivery partners, and traffic conditions using Apache Flink[14]. This capability processes data as it streams in—without waiting for batches—providing customers with instant delivery time estimates.
Another key benefit for Swiggy has been elastic scaling during peak demand periods such as festivals[14][15]. Confluent's platform automatically adjusts resources to match demand spikes, ensuring no data lags or discrepancies disrupt Swiggy's ecosystem even under extreme load conditions[15]. Additionally, improved visibility into data flow helps Swiggy detect and resolve workflow inefficiencies, while Confluent's one-click governance capabilities ensure secure and controlled data management[15].
Beyond Swiggy, Current Bengaluru showcased how other Indian companies are leveraging Confluent's platform to transform their operations. Representatives from companies including Uber, Dream11, PhonePe, and Shiprocket shared their real-world experiences implementing data streaming solutions[1][2]. These sessions provided practical insights into navigating implementation challenges and maximizing the value of data streaming technologies across various industry contexts.
The event highlighted how Confluent is enabling these organizations to meet the evolving expectations of modern consumers in 2025—particularly in fast-moving industries where real-time data processing is crucial for competitive advantage[14]. Today's consumers, shaped by a digital-first world, demand more than speed; they expect predictability, clarity, and personalized experiences that can only be delivered through sophisticated real-time data systems[14].
A dominant theme throughout Current Bengaluru was the critical role of data streaming in powering AI applications and innovations. According to Confluent's 2024 Data Streaming Report highlighted at the event, 90% of respondents believe data streaming platforms can lead to more product and service innovation in AI and ML development[13]. This represents a significant shift in how organizations view data streaming—no longer as just an operational technology but as a strategic enabler for advanced AI capabilities.
The conference emphasized how data streaming is evolving from a specialized technology to a foundational component of enterprise architecture. With 86% of respondents citing data streaming as a strategic or important priority for IT investments and 91% viewing data streaming platforms as critical for achieving data-related goals, the technology is clearly moving into the mainstream of enterprise data strategy[13]. This perspective was reinforced through numerous technical sessions and customer stories demonstrating how organizations are leveraging data streaming to build and deploy AI-powered applications.
Speakers at the event highlighted how traditional batch processing models are undergoing significant changes, with customers eager to adopt cutting-edge technology that enables real-time processing[11]. The year 2025 was positioned as potentially being an "inflection year" for this transformation, particularly with the growing demand for real-time processing driven by AI advancements[11]. As Jay Kreps noted in his keynote, "We're all about making your data work for you, whenever you need it and in whatever format is required"[7].
Current Bengaluru also provided insights into the broader data streaming ecosystem and its evolution heading into 2025 and beyond. The event highlighted emerging trends such as new startups developing around the Kafka protocol, the growth of streaming databases like Materialize and RisingWave, and the expansion of Stream Processing SaaS providers[12]. Traditional data management vendors like MongoDB and Snowflake were also discussed as they attempt to incorporate streaming capabilities into their offerings[12].
The conference emphasized how the deployment model for data streaming is evolving from self-managed, partially managed, and fully managed approaches to a more streamlined categorization of self-managed, BYOC (Bring Your Own Cloud), and cloud-native solutions[12]. This reflects the maturing of the market and the increasing importance of cloud-native approaches for modern data architectures.
Current Bengaluru 2025 showcased Confluent's significant investment and growth in the Indian market. The company announced that it had exceeded its India headcount target for 2024, growing staff by more than 50% against an initial plan of 25%[9]. This growth was driven by increasing demand across sectors such as BFSI (Banking, Financial Services, and Insurance), digital-native firms, and telecom companies[9].
Building on this momentum, Confluent announced plans to expand its India workforce by at least another 20% in 2025, with roles spanning engineering, sales, customer solutions, finance, operations, legal, and marketing functions[9]. This expansion reflects India's strategic importance to Confluent's global operations, with engineering teams in India fully managing the company's Confluent Platform and Connect portfolio[9]. Jay Kreps emphasized this point during the event, noting that "a highly talented team in India" represents "not just engineering but all parts of the company"[9].
The event highlighted Confluent's growing business presence in India, with customers including prominent companies like Swiggy, Meesho, and MPL[9]. The company's recent partnership with Jio Platforms to support Jio Cloud Services further demonstrates its commitment to the Indian market[9]. Rubal Sahni, Area Vice President and Country Manager for Confluent India, noted emerging opportunities beyond the company's traditional focus areas: "GCCs, legacy enterprises, manufacturing, and IoT use cases are seeing a surge in adoption. These verticals are becoming key revenue contributors alongside our core focus areas like BFSI, telcos, and digital natives"[9].
This regional growth reflects Confluent's strong global business performance, with subscription revenue rising 24% to USD 251 million in the fourth quarter of 2024, while Confluent Cloud revenue increased 38% to USD 138 million[9]. The company achieved a non-GAAP operating margin of 5%, marking its third consecutive quarter of positive margin[9]. These results underscore the growing market demand for data streaming technologies and Confluent's leadership position in this expanding space.
Current Bengaluru offered attendees a rich array of learning experiences through more than 35 technical sessions delivered by distinguished engineers, architects, and community leaders[1][2]. These sessions ranged from short lightning talks to in-depth technical deep dives, providing practical insights and implementation guidance for organizations at various stages of their data streaming journey[1][3]. Presentations from tech practitioners at companies like Swiggy, Uber, Dream11, PhonePe, and Shiprocket offered valuable real-world perspectives on implementing and scaling data streaming solutions[1][2].
The event featured tailored content streams based on experience levels, job roles, and industries, ensuring relevance for a diverse audience of attendees[6]. Technical sessions covered key technologies including Apache Kafka, Apache Flink, and Apache Iceberg, with a particular focus on how these technologies can power real-time applications and generative AI use cases[1][3]. Attendees also had the opportunity to explore the latest tools and solutions through an expo hall featuring technology providers across the data streaming ecosystem[1][2].
Beyond technical content, Current Bengaluru featured several initiatives aimed at fostering community connection and inclusivity. A notable highlight was the Women in Tech Lunch hosted by Confluent's Women's Inclusion Network, offering career and leadership advice from industry leaders[1][2]. This event underscores Confluent's commitment to promoting diversity and inclusion within the technology sector and the data streaming community specifically.
The conference also included networking opportunities for attendees to connect with data streaming enthusiasts and discover new ways to leverage data in real-time[1][2]. These community-building activities are particularly significant given India's prominence in the global Kafka ecosystem—with more than 30% of the world's Kafka community members located in APAC and India alone being home to the second largest Kafka community globally, after the U.S.[4].
Current Bengaluru 2025 showcased Confluent's vision for data streaming as a foundational technology enabling real-time applications, advanced analytics, and AI innovations. The event highlighted how data streaming is evolving from a specialized technology to an essential component of modern data architecture, particularly as organizations seek to deliver more responsive, personalized experiences to their customers.
The product announcements, partnerships, and customer stories presented at the conference demonstrate the growing maturity and business impact of data streaming technologies. As organizations increasingly prioritize real-time data processing to drive decision-making and customer experiences, platforms like Confluent are positioned to play a central role in the next generation of enterprise applications.
With its significant investments in India and strategic focus on emerging technologies like AI, Confluent appears well-positioned to capitalize on the growing demand for data streaming solutions. Current Bengaluru 2025 not only showcased the company's current capabilities but also provided a glimpse into how data streaming will continue to transform businesses and industries in the years ahead.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
-
Confluent Announces General Availability of Confluent Cloud for Apache Flink
-
Confluent and Databricks Partner to Usher in New Age of Real-time
-
New Confluent Global Report Finds Data Streaming Accelerates AI Development
-
Confluent GA's Tableflow, Adds Flink Native Inference in Bengaluru
-
Confluent Launches Tableflow to Bridge Real-time Data and AI
-
How Confluent Elevates Data Streaming: Insights from CEO Jay Kreps
-
Confluent Current 2023: A Journey Around the Data Streaming Universe
-
AI-Driven Businesses Must Rethink Data Handling: Confluent's Jay Kreps