Kafka API Guide: Usage & Best Practices
Kafka APIs serve as the foundation for building robust, scalable data streaming applications. These interfaces enable developers to produce, consume, and process real-time data streams with high throughput and fault tolerance. This guide explores the various Kafka APIs, their implementation details, and best practices for optimal performance and reliability.
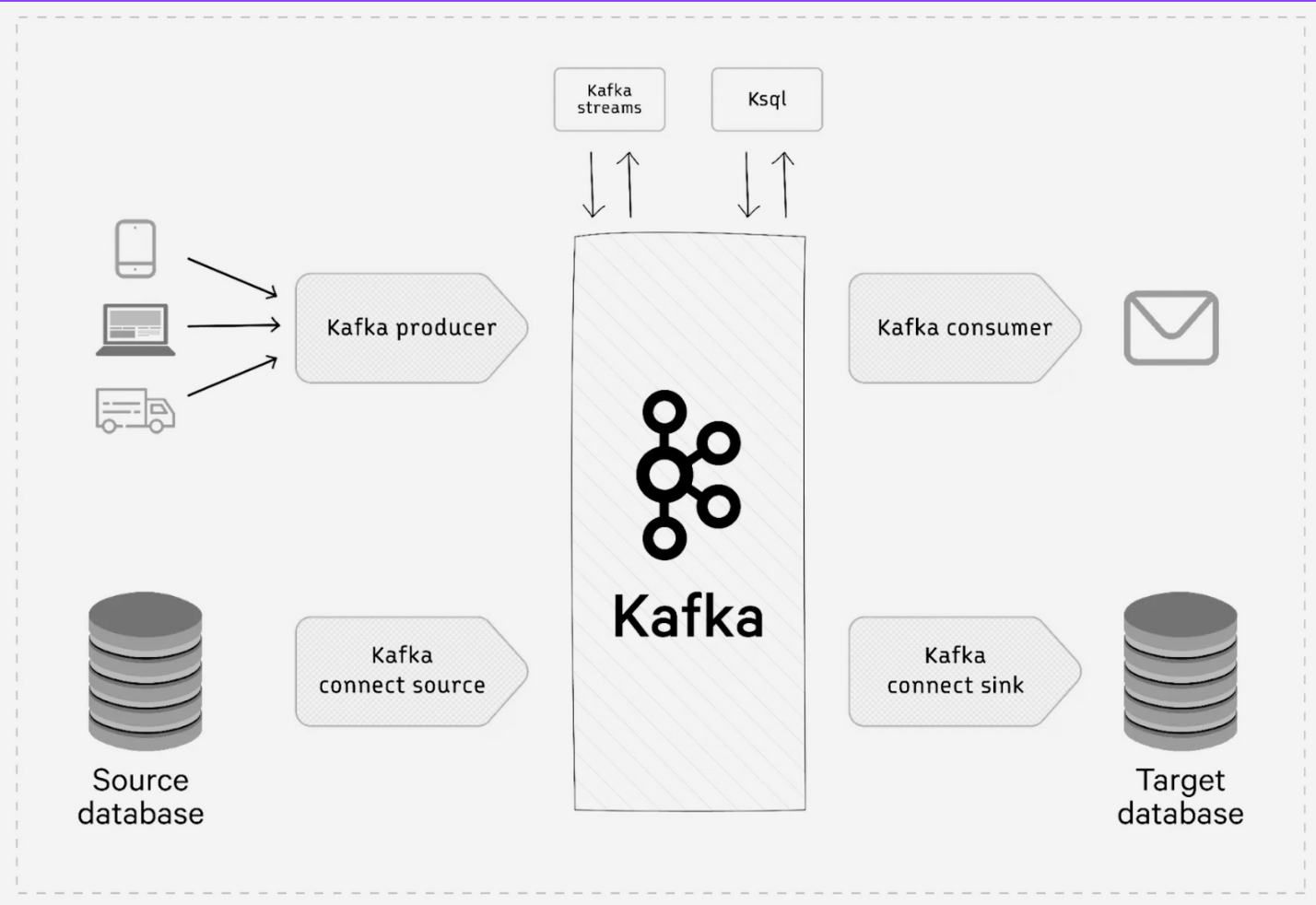
Apache Kafka provides five core APIs, each serving distinct functions within the Kafka ecosystem. These APIs form the backbone of Kafka's functionality, allowing applications to interact with the messaging platform in various ways.
|
API Type |
Primary Function |
Key Use Cases |
|---|---|---|
| Producer API |
Sends streams of data to Kafka topics |
Data ingestion, event publishing, message broadcasting |
| Consumer API |
Reads data streams from Kafka topics |
Event processing, data analytics, notifications |
| Streams API |
Transforms data streams between topics |
Real-time data transformation, filtering, aggregation |
| Connect API |
Integrates with external systems |
Database synchronization, legacy system integration, data pipelines |
| Admin API |
Manages Kafka resources |
Topic creation/deletion, configuration management, ACL administration |
These APIs provide a comprehensive toolkit for building sophisticated data streaming applications, from simple publish-subscribe patterns to complex stream processing workflows.
The Producer API enables applications to send data streams to Kafka topics. It provides mechanisms for serializing, partitioning, and batching messages for efficient delivery.
Here's a basic Java implementation of a Kafka producer:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("myTopic", "key", "value");
producer.send(record, (metadata, exception) -> {
if (exception != null) {
System.out.println("Send failed: " + exception);
} else {
System.out.println("Message sent to partition " + metadata.partition() +
" with offset " + metadata.offset());
}
});
producer.flush();
producer.close();
This example demonstrates setting up a producer with basic configurations, creating a record, and asynchronously sending it with a callback to handle delivery status[1][8].
Properly configuring producers is crucial for reliability and performance:
|
Configuration Parameter |
Recommended Setting |
Purpose |
|---|---|---|
| acks |
"all" |
Ensures message durability by requiring acknowledgment from all in-sync replicas |
| retries |
Maximum value for critical data |
Prevents data loss due to transient failures |
| enable.idempotence |
TRUE |
Prevents message duplication during retries |
| compression.type |
"snappy" or "lz4" |
Reduces bandwidth usage and storage costs |
| batch.size |
16384 to 65536 bytes |
Optimizes throughput by batching messages |
|
linger.ms |
5-100ms |
Improves batching by adding small delays |
For high-throughput scenarios, consider increasing socket buffer sizes:
receive.buffer.bytes=8388608 # 8MB for high-bandwidth networks
This is particularly important when the network's bandwidth-delay-product is larger than a local area network[2].
The Consumer API allows applications to read data from Kafka topics, with support for consumer groups for scalable, fault-tolerant consumption.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("myTopic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
}
This code creates a consumer that subscribes to a topic and continuously polls for new records[1].
|
Configuration Parameter |
Recommended Setting |
Purpose |
|---|---|---|
| auto.offset.reset |
"earliest" or "latest" |
Controls behavior when no offset is found |
| fetch.min.bytes |
1024 to 4096 |
Reduces network overhead by batching fetches |
| max.poll.records |
300-500 for complex processing |
Prevents rebalance timeouts by limiting batch size |
| isolation.level |
"read_committed" |
Ensures exactly-once semantics when working with transactions |
|
session.timeout.ms |
10000-30000ms |
Balances failover speed with stability |
Ensure your consumers are running Kafka version 0.10 or newer to avoid "rebalance storms" caused by bugs in older versions[2].
The Kafka Streams API provides a high-level abstraction for stream processing, allowing stateful operations like joins, aggregations, and windowing.
-
KStream : Represents an unbounded sequence of key-value pairs
-
KTable : Represents a changelog stream with the latest value for each key
-
GlobalKTable : Similar to KTable but replicated entirely to each instance
-
Processor API : Lower-level API for custom processing logic
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
KStream<String, String> transformed = source.mapValues(value -> value.toUpperCase());
transformed.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
This simple example reads from an input topic, transforms each message by converting it to uppercase, and writes to an output topic.
Kafka provides "exactly once" semantics through transaction support, ensuring messages are processed exactly once even in the face of failures.
For transactional producers:
props.put("transactional.id", "my-transactional-id");
producer.initTransactions();
producer.beginTransaction();
// Send records
producer.commitTransaction();
For Kafka Streams applications:
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE);
This configuration enables transactional processing in Kafka Streams applications, providing end-to-end exactly-once semantics for stream processing pipelines[4].
Kafka Connect provides a framework for integrating Kafka with external systems like databases, key-value stores, and search indexes.
-
Source Connectors : Import data from external systems to Kafka (JDBC, MongoDB, Elasticsearch)
-
Sink Connectors : Export data from Kafka to external systems (HDFS, S3, JDBC)
The Admin API allows programmatic management of Kafka resources like topics, brokers, and ACLs.
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
AdminClient admin = AdminClient.create(props);
// Create a topic
NewTopic newTopic = new NewTopic("new-topic", 3, (short)3);
admin.createTopics(Collections.singleton(newTopic));
// List topics
ListTopicsResult topics = admin.listTopics();
Set<String> topicNames = topics.names().get();
// Delete topics
admin.deleteTopics(Collections.singleton("topic-to-delete"));
Securing Kafka implementations is crucial for protecting sensitive data. Key security practices include:
-
Authentication : Implement SSL/TLS, SASL, or OAuth for client authentication
-
Authorization : Use ACLs to control access to topics and resources
-
Network Security : Configure firewalls and network segmentation
-
Data Encryption : Enable SSL for encryption in transit
-
PII Protection : Implement data masking for personally identifiable information
For human access, tools like Conduktor Console can streamline permissions management, while PII masking can help maintain compliance with privacy laws while still allowing developers to debug issues[5].
Kafka's APIs are available in multiple languages, with varying levels of feature support:
|
Language |
Official Client |
Notable Features |
|---|---|---|
| Java |
kafka-clients |
Full feature support, reference implementation |
| Python |
confluent-kafka-python |
Supports transactions and exactly-once semantics |
| Go |
confluent-kafka-go |
High performance, C-based implementation |
| .NET |
confluent-kafka-dotnet |
Full feature compatibility on Windows |
Confluent's Python client supports advanced features like exactly-once processing using the transactional API and integration with asyncio for asynchronous programming[4].
Effective monitoring is essential for maintaining healthy Kafka deployments. Key metrics to track include:
-
Producer and consumer lag
-
Request rates and errors
-
Network throughput
-
Disk usage and I/O
-
GC pauses and JVM metrics
Tools like Conduktor provide visibility into these metrics through their API interfaces[7].
Kafka's APIs provide a powerful toolkit for building real-time data streaming applications. By understanding the core APIs—Producer, Consumer, Streams, Connect, and Admin—developers can leverage Kafka's full potential for high-throughput, fault-tolerant data processing.
When implementing Kafka-based solutions, follow the best practices outlined in this guide: properly configure your producers and consumers, implement appropriate error handling, maintain security, and monitor your system's performance. For critical applications, consider enabling exactly-once semantics to ensure data integrity.
By following these guidelines and leveraging the full capabilities of Kafka's APIs, you can build reliable, scalable, and efficient data streaming applications that meet the demands of modern data processing.
Kafka transactions provide robust guarantees for atomicity and exactly-once semantics in stream processing applications. By understanding their underlying concepts, configuration options, common issues, and best practices, developers can leverage Kafka's transactional capabilities effectively. While they introduce additional complexity and overhead, their benefits in ensuring data consistency make them indispensable for critical applications.
This comprehensive exploration highlights the importance of careful planning and monitoring when using Kafka transactions, ensuring that they align with application requirements and system constraints.
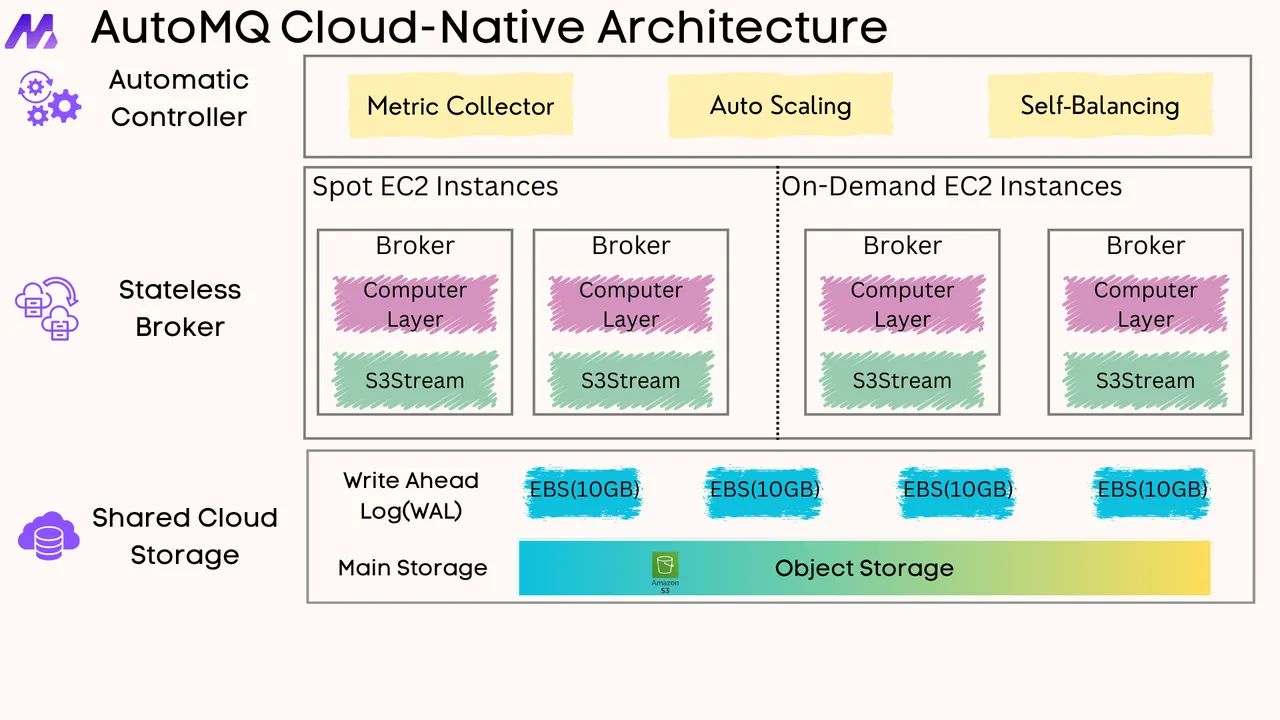
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging