Kafka Logs: Concept & How It Works & Format
Apache Kafka has become a cornerstone technology for building high-performance, real-time data pipelines and streaming applications. At its core, Kafka's powerful capabilities are built upon its sophisticated log management system. This comprehensive blog explores Kafka logs in depth, covering fundamental concepts, internal mechanisms, configuration options, best practices, and common challenges.
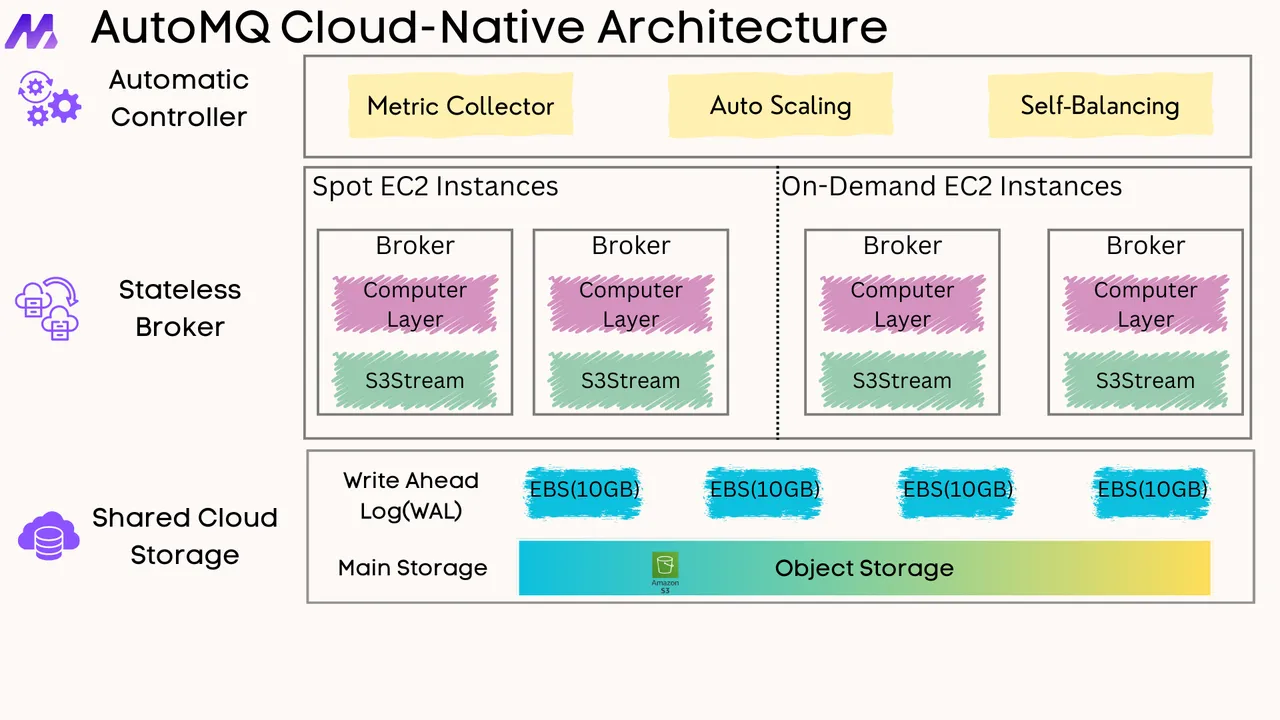
Kafka's architecture revolves around its implementation of distributed, append-only logs. Despite the name, Kafka logs are not traditional application log files that record system events. Instead, they represent immutable data structures that hold messages distributed across multiple servers in a cluster[1]. These logs form the foundation of Kafka's reliability, scalability, and performance characteristics.
In Kafka's terminology, a topic is essentially a named log to which records are published. Each topic is further divided into partitions to enable parallelism in both producing and consuming data. These partitions are the fundamental unit of parallelism, replication, and fault tolerance in Kafka's architecture[1]. Each partition is an ordered, immutable sequence of records that is continually appended to, forming what is known as a structured commit log[5].
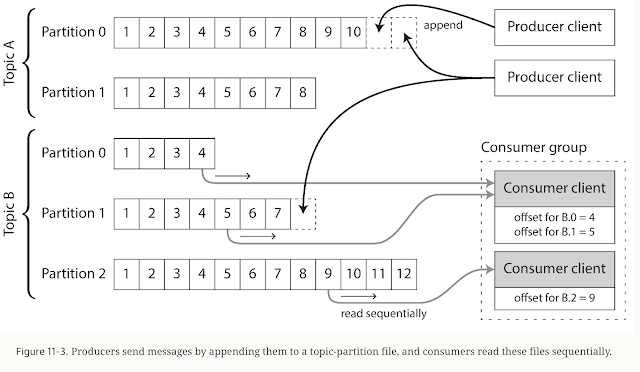
The commit log nature of Kafka means records are appended to the end of logs in a strictly sequential manner. This append-only design provides numerous benefits, including high throughput, as sequential disk operations are much faster than random access patterns. It also enables Kafka to maintain message ordering guarantees (at the partition level) and support for exactly-once semantics[11].
Kafka stores these logs as files on disk. Each topic-partition corresponds to a directory on the broker's filesystem. The directory name follows the pattern topic-partition (e.g., my-topic-0 for partition 0 of a topic named "my-topic")[11]. Inside these directories, Kafka maintains various files that collectively implement the log structure, including the log segments, indexes, and other metadata files.
Kafka's log implementation is more sophisticated than a simple append-only file. Each partition log is further divided into segments, which are the actual files stored on disk. This segmentation improves performance and manageability by breaking large logs into smaller, more manageable pieces[5].
Within each topic partition directory, you'll find multiple files that make up the log segments. These typically include:
-
Log files (.log) - These files contain the actual message data written to the partition. The filename represents the base offset of the first message in that segment. For example,
00000000000000000000.logcontains messages starting from offset 0[11]. -
Index files (.index) - These files maintain mappings between message offsets and their physical positions within the log file. This index allows Kafka to quickly locate messages by their offset without scanning the entire log file[1].
-
Timeindex files (.timeindex) - These files store mappings between message timestamps and their corresponding offsets, enabling efficient time-based retrieval of messages[1].
- Leader-epoch-checkpoint files These files contain information about previous partition leaders and are used to manage replica synchronization and leader elections[1].
Additionally, active segments may have snapshot files that store producer state information, which is critical during leader changes and for implementing exactly-once semantics[1].
At any given time, each partition has one designated "active segment" to which new messages are appended. Once a segment reaches a configured size or age threshold, Kafka closes it and creates a new active segment[1]. This rolling mechanism is crucial for implementing log retention policies and managing storage efficiently.
The architecture of segments provides several advantages:
-
Efficient deletion of older records through segment-based deletion
-
Improved read performance as consumers often read from recent segments
-
Better storage management through controlled file sizes
-
Enhanced recovery capabilities through segment-based recovery processes[5]
Understanding the operational mechanisms of Kafka logs requires examining the write and read paths, as well as the underlying storage processes.
When a producer sends a message to a Kafka topic, the broker appends it to the active segment of the appropriate partition. The append operation involves:
-
Writing the message to the end of the log file
-
Updating the offset index to map the message's offset to its physical position
-
Updating the timestamp index to map the message's timestamp to its offset
-
Periodically flushing the data to disk based on configured synchronization settings[1]
This sequential append operation is highly efficient, contributing to Kafka's high throughput capabilities. Messages are never modified after being written - a property that simplifies replication and consumer operations[2].
When a consumer reads from a partition, it specifies an offset to start from. Kafka uses the index files to quickly locate the corresponding message in the log files:
-
The consumer requests messages starting from a specific offset
-
Kafka uses the offset index to find the closest preceding offset entry
-
It then scans forward from that position to find the exact offset requested
-
Messages are then read sequentially from that point onward[1]
The timeindex file similarly enables efficient time-based queries, allowing consumers to request messages from a specific timestamp[1].
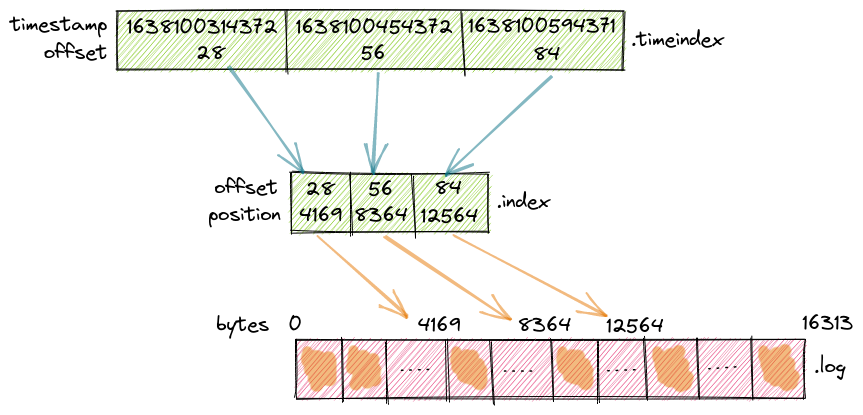
Kafka's log directory structure follows a hierarchical pattern:
log.dirs/
├── mytopic-0/ # Directory for partition 0 of "mytopic"
│ ├── 00000000000000000000.log # Log segment starting at offset 0
│ ├── 00000000000000000000.index # Index for the segment
│ ├── 00000000000000000000.timeindex # Timestamp index for the segment
│ ├── 00000000000000123456.log # Next log segment starting at offset 123456
│ ├── 00000000000000123456.index # Index for the next segment
│ └── 00000000000000123456.timeindex # Timestamp index for the next segment
├── mytopic-1/ # Directory for partition 1 of "mytopic"
└── ...
This structure allows Kafka to manage multiple topics and partitions efficiently on disk[3][4].
Kafka provides numerous configuration parameters to fine-tune log behavior according to specific use cases and performance requirements.
The most fundamental configuration is where logs are stored:
-
log.dirsSpecifies one or more directories where partition logs are stored -
log.dirA single directory (used if log.dirs is not set)[4]
By default, Kafka stores logs in /tmp/kafka-logs , but production deployments should use more permanent locations with sufficient disk space[3].
To control how segments are created and managed:
-
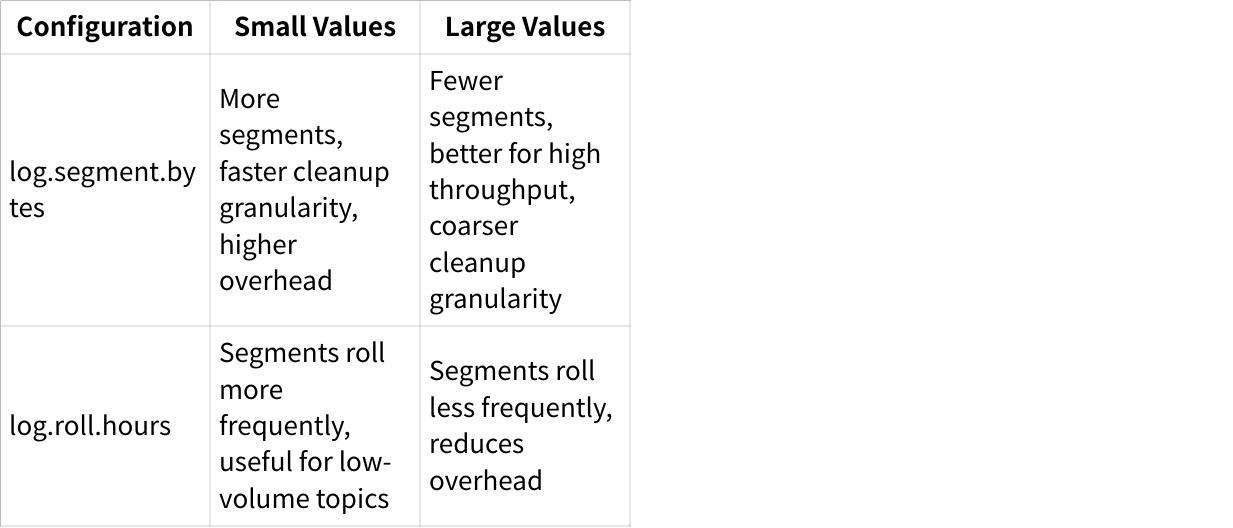
log.segment.bytesMaximum size of a single segment file (default: 1GB) -
log.roll.msorlog.roll.hoursTime-based threshold for rolling segments (default: 7 days)[1]
Kafka creates a new segment when either the size or time threshold is reached, whichever comes first. Segment size has significant performance implications:
To control how long data is retained:
-
log.retention.bytesMaximum size before old segments are deleted -
log.retention.ms,log.retention.minutes, orlog.retention.hoursTime-based retention (default: 7 days)[1]
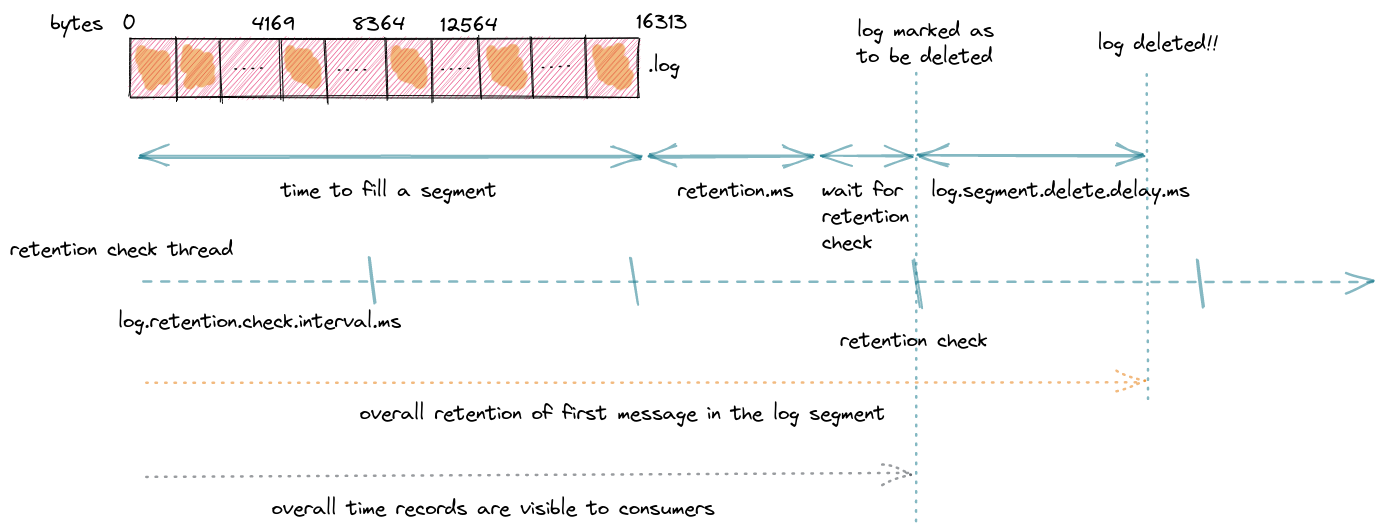
Kafka retains messages for at least the configured retention time, but actual deletion may be delayed because:
-
Retention is segment-based, not message-based
-
The retention time applies to the last message in a segment
-
Actual deletion occurs after a delay specified by
log.segment.delete.delay.ms[1]
Kafka supports two cleanup policies to manage old data:
-
Delete policy : Removes segments older than the retention period
-
Compact policy : Retains only the latest value for each message key[1][5]
The cleanup policy is configured with cleanup.policy at the topic level, and can be set to either "delete", "compact", or "delete,compact" for a combination of both approaches[5].
While deletion is straightforward (removing segments based on time or size), compaction deserves special attention as it provides unique capabilities for specific use cases.
Log compaction ensures that Kafka retains at least the last known value for each message key within the topic partition. It works by periodically scanning log segments and creating compacted segments that contain only the latest value for each key[6].
For example, if a topic contains the following messages with the same key:
123 => [email protected]
123 => [email protected]
123 => [email protected]
After compaction, only the last message (123 => [email protected]) would be retained[5].
The compaction process involves specialized "cleaner threads" that:
-
Scan log segments in the background
-
Build an in-memory index of message keys and their latest offsets
-
Create new, compacted segments containing only the latest value for each key
-
Replace the old segments with the compacted ones[7]
Key configuration parameters for log compaction include:
-
log.cleaner.enableEnables or disables the log cleaner (compaction) -
log.cleaner.min.cleanable.ratioMinimum ratio of dirty records to total records before a segment is eligible for cleaning -
log.clean.min.compaction.lag.msMinimum time a message must remain uncompacted -
log.cleaner.threadsNumber of background threads to use for compaction[6]
The cleaner's behavior can be fine-tuned to balance throughput, latency, and resource usage. For example, increasing log.cleaner.min.cleanable.ratio reduces the frequency of compaction but may lead to higher storage usage temporarily[6].
Besides the data logs that store messages, Kafka also generates application logs that help monitor and troubleshoot the system itself. These application logs are entirely separate from the commit logs discussed earlier.
Kafka generates several types of application logs:
-
Server logs : General broker operations and errors
-
Controller logs: Operations performed by the controller broker
-
State change logs : Records of resource state changes (topics, partitions, etc.)
-
**Request logs: ** Client request processing details[8]
Each log type provides different insights into Kafka's operations. For example, the state change log (logs/state-change.log) is particularly useful for troubleshooting partition availability issues[8].
Kafka components use the Log4j framework for application logging. The default configuration files are:
-
log4j.propertiesFor Kafka brokers and ZooKeeper -
connect-log4j.propertiesFor Kafka Connect and MirrorMaker 2[9]
These files can be found in the config directory of your Kafka installation. To adjust logging levels, modify the appropriate Log4j property file or use environment variables to specify alternate configurations:

For example, to specify a custom Log4j configuration for a Kafka broker:
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:/path/to/custom-log4j.properties" \\ ./bin/kafka-server-start.sh ./config/server.properties
Effective management of Kafka logs is crucial for maintaining optimal performance, reliability, and resource utilization.
-
Separate data directories : Use separate disks for Kafka data logs and application logs to prevent application logging from impacting message throughput
-
Allocate sufficient space : Calculate storage needs based on message rate, size, and retention period
-
Use multiple log directories : Spread logs across multiple disks using
log.dirsto improve I/O parallelism[1]
-
Adjust segment size based on workload : Use smaller segments (256MB-512MB) for low-volume topics and larger segments (1GB+) for high-throughput topics
-
Balance retention granularity and overhead : Smaller segments provide more precise retention but create more files to manage
-
Consider segment rolling impact : Very frequent rolling creates overhead, while infrequent rolling may delay log compaction or deletion[2]
-
Set retention based on business requirements : Consider compliance, replay needs, and storage constraints
-
Use time-based retention for most cases : Simpler to reason about than size-based retention
-
Implement topic-specific retention : Override cluster defaults for critical topics using topic-level configuration[3]
-
Use appropriate log levels : Set INFO for production and DEBUG/TRACE for troubleshooting
-
Implement log rotation : Ensure application logs don't consume excessive disk space
-
Centralize log collection : Aggregate application logs for easier monitoring and analysis[4]
-
Monitor disk usage : Track disk space regularly, especially for high-volume topics
-
Balance log compaction frequency : Too frequent compaction wastes resources, too infrequent compaction delays space reclamation
-
Adjust file descriptors : Ensure sufficient file descriptor limits as each segment requires open file handles[4]
Kafka log management can present several challenges. Understanding common issues and their solutions helps maintain a healthy Kafka cluster.
-
Disk space exhaustion : If logs consume all available space, Kafka brokers may crash or become unresponsive. Solutions include increasing retention, adding storage, or implementing topic-level quotas.
-
Too many open files : Large numbers of segments can exceed OS file descriptor limits. Increase the ulimit setting or consolidate to fewer, larger segments.
-
Slow deletion : Log deletion happens asynchronously and segment-by-segment, which may not free space quickly enough during emergencies. Manual intervention may be required in extreme cases[5]
-
Delayed compaction : If the cleaner threads can't keep up with the data rate, compaction may lag behind. Adjust
log.cleaner.threadsandlog.cleaner.io.max.bytes.per.second. -
High memory usage : The compaction process builds in-memory maps of keys, which can consume significant memory for topics with many unique keys. Use
log.cleaner.dedupe.buffer.sizeto control this[6] -
Missing records : If records appear to be missing after compaction, check if they had the same key as newer records (and were thus compacted away)[7]
-
Offsets beyond retention period : If consumers try to read from offsets that have been deleted due to retention policies, they'll encounter
OffsetOutOfRangeException. Adjust retention or consumer restart behavior. -
Compaction confusion : Consumers may be confused by compacted logs if they expect all messages to still be present. Design consumers with compaction semantics in mind[8]
-
Excessive logging : Verbose logging levels (especially DEBUG) can impact performance and create large log files. Use appropriate levels and monitor log growth.
-
Missing context : Default log formats may not include enough context for troubleshooting. Consider customizing log formats to include more details[9]
-
Log directory fills up : Application logs can consume all available space on the system partition. Implement log rotation and monitoring[5]
Kafka's log management system is a fundamental component that enables its powerful streaming capabilities. Understanding Kafka logs—from the basic concepts to the intricate details of configuration and troubleshooting—is essential for operating Kafka effectively.
The log-centric design of Kafka provides numerous advantages: high throughput, durability, scalability, and simplified consumer semantics. By properly configuring log segments, retention policies, and compaction processes, organizations can optimize Kafka for their specific use cases while maintaining reliable performance.
As with any complex system, challenges will arise. By following best practices and knowing how to troubleshoot common issues, operators can ensure their Kafka clusters remain healthy and performant, even as data volumes grow and requirements evolve.
For those looking to deepen their understanding of Kafka logs, exploring the official documentation and tools from providers like Confluent, AutoMQ, Redpanda, and Conduktor is highly recommended. These resources provide additional insights and advanced techniques for mastering Kafka's powerful log management capabilities.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays