Kafka Replication: Concept & Best Practices
Kafka replication is a critical mechanism for ensuring data reliability, fault tolerance, and high availability in distributed streaming systems. This comprehensive blog examines the fundamental concepts, implementation details, configuration options, and best practices for Kafka replication based on industry expertise and authoritative sources.
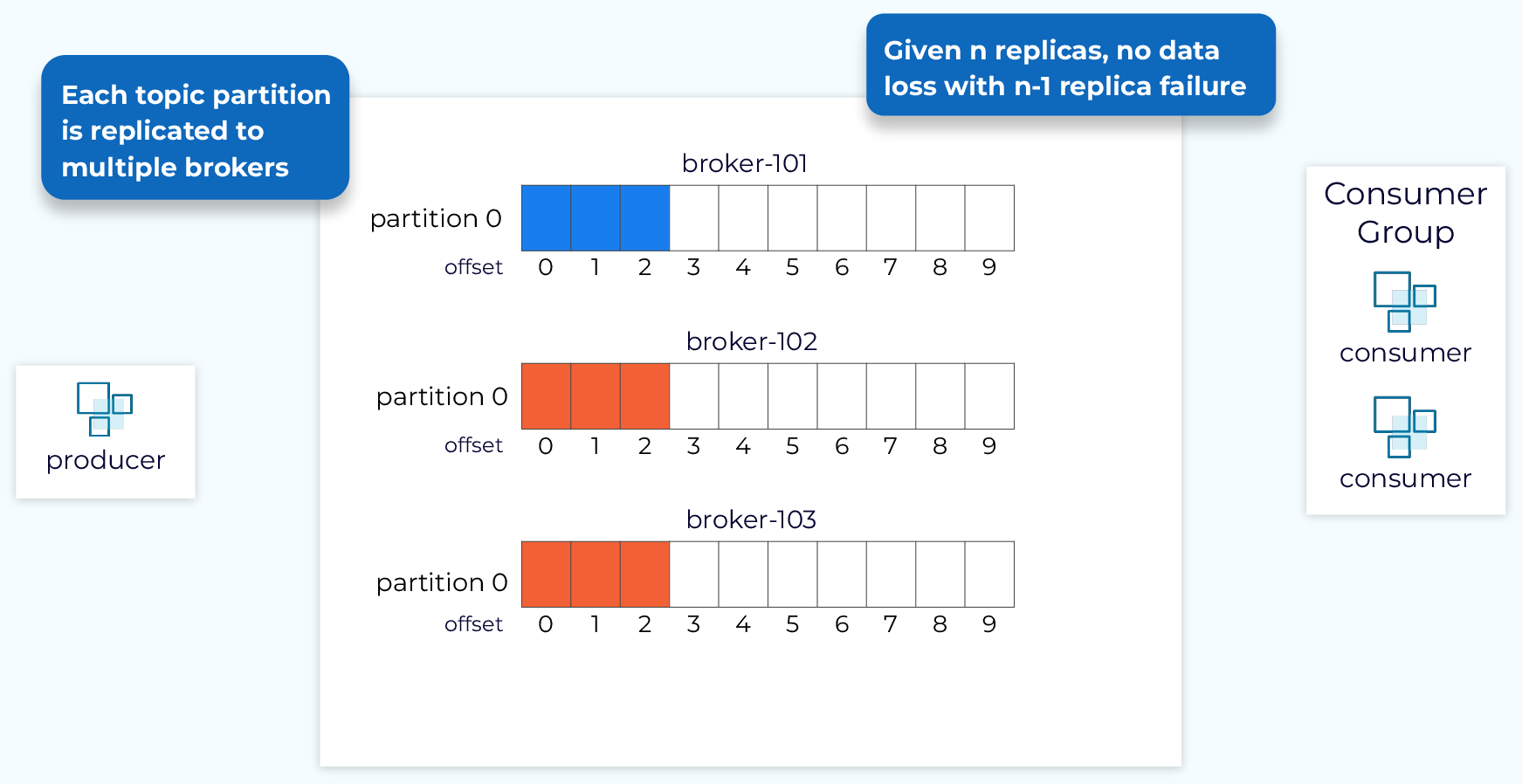
Replication in Kafka means that data is written not just to one broker, but to multiple brokers[3]. This redundancy enables Kafka clusters to maintain data availability even when individual brokers fail. The number of copies maintained for a partition is determined by the replication factor, which is specified at topic creation time[3].
The replication factor is a critical topic-level setting that determines the number of copies of data that will be maintained across the Kafka cluster:
-
A replication factor of 1 means no replication, typically used only in development environments[3]
-
A replication factor of 3 is considered the industry standard, providing an optimal balance between fault tolerance and overhead[3][8]
This redundancy allows Kafka to withstand broker failures without data loss. For example, with a replication factor of 3, two brokers can fail while still maintaining data access[9].
Each partition in Kafka has one broker designated as the leader and others as followers:
-
Leader : Handles all read and write requests for a specific partition[9][14]
-
Followers : Replicate data from the leader to maintain synchronized copies[9][14]
When the leader fails, one of the followers can take over leadership to maintain availability[14]. This leader-follower architecture is fundamental to Kafka's replication mechanism and provides the foundation for its fault tolerance capabilities.
Kafka's replication protocol operates at the partition level, which serves as the unit of replication, ordering, and parallelism[15].

When a producer sends a message to a Kafka broker, the message is:
-
Written by the leader broker of the target partition
-
Replicated to all follower replicas of that partition
-
Considered "committed" only after it has been successfully copied to all in-sync replicas[6]
The replication process is demonstrated in the diagram described in search result[3], where with three brokers and a replication factor of 2, when a message is written to Partition 0 of a topic in Broker 101, it's also written to Broker 102 because it has Partition 0 as a replica.
The In-Sync Replicas (ISR) is a subset of replicas that are considered "caught up" with the leader:
-
The leader tracks which followers are in the ISR by monitoring their lag
-
A replica is considered "in-sync" if it's actively fetching data and not lagging significantly behind the leader
-
Only replicas in the ISR are eligible to be elected as the new leader if the current leader fails[6]
The ISR concept is crucial because it ensures that any replica promoted to leader has all committed messages, maintaining data consistency across broker failures.
Follower replicas synchronize with the leader through a pull-based mechanism:
-
Followers send fetch requests to the leader
-
The leader responds with new messages since the last fetch
-
Followers write these messages to their local logs
-
Followers update their offset positions to reflect their current state[6][9]
This pull-based approach allows followers to replicate data at their own pace while still maintaining the ordering guarantees that Kafka provides.
Configuring replication correctly is essential for achieving the right balance between reliability and performance in Kafka deployments.
The following table summarizes key configuration parameters related to Kafka replication:
|
Parameter |
Description |
Default |
Recommended |
|---|---|---|---|
| default.replication.factor |
Default factor for auto-created topics |
1 |
At least 2[5] |
| min.insync.replicas |
Minimum ISRs needed for acks=-1 requests |
1 |
2 (for RF=3)[5] |
| unclean.leader.election.enable |
Allow out-of-sync replicas to become leaders |
FALSE |
false[5] |
|
replica.lag.time.max.ms |
Time threshold before a replica is considered out of sync |
- |
Based on workload[6] |
To increase the replication factor of an existing topic, follow these steps[3]:
-
Describe the current topic configuration:
textkafka-topics --zookeeper ZK_host:2181 --describe --topic TOPICNAME -
Create a JSON file with new replica assignment:
json{ "version":1, "partitions":\[ {"topic":"TOPICNAME","partition":0,"replicas":\[1039,1040\]} \] } -
Execute the reassignment plan:
textkafka-reassign-partitions.sh --zookeeper ZK_host:2181 --bootstrap-server broker_host:9092 --reassignment-json-file /path/to/file.json --execute -
Verify the reassignment:
textkafka-reassign-partitions.sh --zookeeper ZK_host:2181 --bootstrap-server broker_host:9092 --reassignment-json-file /path/to/file.json --verify
This process allows you to safely increase redundancy for critical topics without downtime[2][3].
For organizations requiring multi-datacenter deployments or disaster recovery capabilities, several tools facilitate replication between Kafka clusters.
Confluent Replicator is a battle-tested solution for replicating Kafka topics between clusters1[7]. Key features include:
-
Topic selection using whitelists, blacklists, and regular expressions
-
Dynamic topic creation in destination clusters with matching configuration
-
Automatic resizing when partition counts change in source clusters
-
Automatic reconfiguration when topic settings change in source clusters[7]
Replicator leverages the Kafka Connect framework and provides a more comprehensive solution compared to basic tools like MirrorMaker1[16].
MirrorMaker is a standalone tool that connects Kafka consumers and producers to enable cross-cluster replication[16]. It:
-
Reads data from topics in the source cluster
-
Writes data to topics with identical names in the destination cluster
-
Provides basic replication capabilities without advanced configuration management[16][17]
For organizations using Redpanda (a Kafka-compatible streaming platform), the MirrorMaker2 Source connector provides[10]:
-
Replication from external Kafka or Redpanda clusters
-
Topic creation on local clusters with matching configurations
-
Replication of topic access control lists (ACLs)[10]
Implementing proper replication strategies is crucial for maintaining reliable and performant Kafka clusters.
-
Deploy across multiple availability zones : Configure your cluster across at least three availability zones for maximum resilience[8]
-
Minimum broker count : Maintain at least three brokers in production environments[5]
-
Client configuration : Ensure client connection strings include brokers from each availability zone[8]
-
Right-sizing : Follow broker size recommendations for partition counts[8]
-
Production environments : Use a replication factor of 3 for all production topics[3][5]
-
Development environments : A replication factor of 1 may be acceptable but not recommended[3]
-
Critical data : Consider higher replication factors (4-5) for extremely critical data, though this increases storage and network requirements[9]
Understanding how many broker failures your system can tolerate is essential:
-
With a replication factor of N and min.insync.replicas=M, your cluster can tolerate N-M broker failures while maintaining write availability[9]
-
For example, with RF=3 and min.insync.replicas=2, you can lose 1 broker and still accept writes[9]
-
Monitor under-replicated partitions : This metric should be zero during normal operations; non-zero values indicate potential issues[6]
-
Proper partition count : Balance between parallelism and overhead; more partitions increase throughput but add replication latency[12]
-
Avoid over-partitioning : Excessive partitions lead to more replication traffic, longer rebalances, and more open server files[12]
-
Express configs in user terms : Configure parameters based on what users know (like time thresholds) rather than what they must guess (like message counts)[6]
Even with proper configuration, Kafka replication can encounter several challenges that administrators should be prepared to address.
Replicas may fall out of sync for several reasons:
-
Network latency or congestion
-
Broker resource constraints (CPU, memory, disk I/O)
-
Large message batches arriving faster than replication can handle[6]
The improved approach defines lag in terms of time rather than message count, reducing false alarms from traffic spikes[6].
When a broker fails, a new partition leader must be elected:
-
Only in-sync replicas are eligible for leadership by default
-
The
unclean.leader.election.enableparameter controls whether out-of-sync replicas can become leaders as a last resort -
Allowing unclean leader election risks data loss but improves availability[5]
For geo-distributed deployments, consider:
-
Using dedicated tools like Confluent Replicator rather than basic MirrorMaker[16][17]
-
Active-active configurations for geographically distributed access with low latency[7]
-
Disaster recovery setups with standby clusters in different regions[10]
Kafka replication is fundamental to building reliable, fault-tolerant streaming systems. By properly configuring replication factors, managing in-sync replicas, and following best practices, organizations can achieve the right balance between data durability, availability, and performance.
The industry standard recommendation of a replication factor of 3 with min.insync.replicas=2 provides an optimal balance for most production workloads. For cross-datacenter scenarios, specialized tools like Confluent Replicator offer robust capabilities for maintaining consistency across distributed environments.
As with any distributed system, ongoing monitoring and maintenance of the replication process is essential to ensure continued reliability and performance as workloads evolve.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging

-
Hands-Free Kafka Replication: A Lesson in Operational Simplicity
-
Setting Up Replication and Disaster Recovery Using Redpanda MirrorMaker Source Connector
-
Hiya's Best Practices Around Kafka Consistency and Availability
-
Migrate Data from Apache Kafka MirrorMaker to Confluent Replicator
-
From Apache Kafka MirrorMaker migration to Confluent Replicator
-
Is it Possible to Modify the Number of Partitions and/or Replicas Once a Kafka Topic is Created?
-
Kafka MirrorMaker Setup to Replicate Data Between 2 Redpanda Clusters
-
Cross Cluster Replication with Confluent Kafka: When and How to Use It